The Multilayer Network as a Computational Graph
It is helpful to view a neural network as a computational graph, which is constructed by piecing together many basic parametric models. Neural networks are fundamentally more powerful than their building blocks because the parameters of these models are learned jointly to create a highly optimized composition function of these models. The common use of the term "perceptron" to refer to the basic unit of a neural network is somewhat misleading, because there are many variations of this basic unit that are leveraged in different settings. In fact, it is far more common to use logistic units (with sigmoid activation) and piece-wise / fully linear units as building blocks of these models.
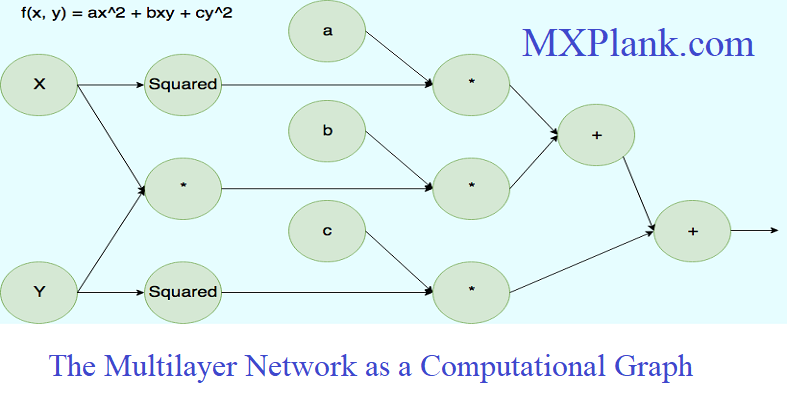
A multilayer network evaluates compositions of functions computed at individual nodes.A path of length 2 in the neural network in which the function
f(.) follows
g(.) can be considered a composition function
f(g(.)).
Furthermore, if
g1(.),
g2...
gk(.) are the functions computed in layerm, and a particular layer-(
m+1) node computes
f(.), then the composition function computed by the layer-(
m+ 1) node in terms of the layer-
m inputs is
f(g1(.),...gk(.)). The use of nonlinear activation functions is the key to increasing the power of multiple layers. If all layers use an identity activation function, then a multi-layer network can be shown to simplify to linear regression.
It has been shown that a network with a single hidden layer of non-linear units (with a wide ranging choice of squashing functions like the sigmoid unit) and a single (linear) output layer can compute almostany "reasonable" function. As a result, neural networks are often referred to as universal function approximators, although this theoretical claim is not always easy to translate into practical usefulness. The main issue is that the number of hidden units required to do sois rather large, which increases the number of parameters to be learned. This results inpractical problems in training the network with a limited amount of data. In fact, deeper networks are often preferred because they reduce the number of hidden units in each layeras well as the overall number of parameters
The "building block" description is particularly appropriate for multilayer neural networks. Very often, off-the-shelf softwares for building neural networks provide analysts
with access to these building blocks. The analyst is able to specify the number and type of units in each layer along with an off-the-shelf or customized loss function. A deep neural network containing tens of layers can often be described in a few hundred lines of code.All the learning of the weights is done automatically by the backpropagation algorithm that uses dynamic programming to work out the complicated parameter update steps of the underlying computational graph.
The analyst does not have to spend the time and effort to explicitly work out these steps. This makes the process of trying different types of architectures relatively painless for the analyst. Building a neural network with many of the off-the-shelf softwares is often compared to a child constructing a toy from building blocks that appropriately fit with one another. Each block is like a unit (or a layer of units) with a particular type of activation. Much of this ease in training neural networks is attributable to the backpropagation algorithm, which shields the analyst from explicitly working out the parameter update steps of what is actually an extremely complicated optimization problem.
Working out these steps is often the most difficult part of most machine learning algorithms,and an important contribution of the neural network paradigm is to bring modular thinkinginto machine learning. In other words, the modularity in neural network design translates to modularity in learning its parameters; the specific name for the latter type of modularity is "backpropagation." This makes the design of neural networks more of an (experienced)
engineer's task rather than a mathematical exercise.